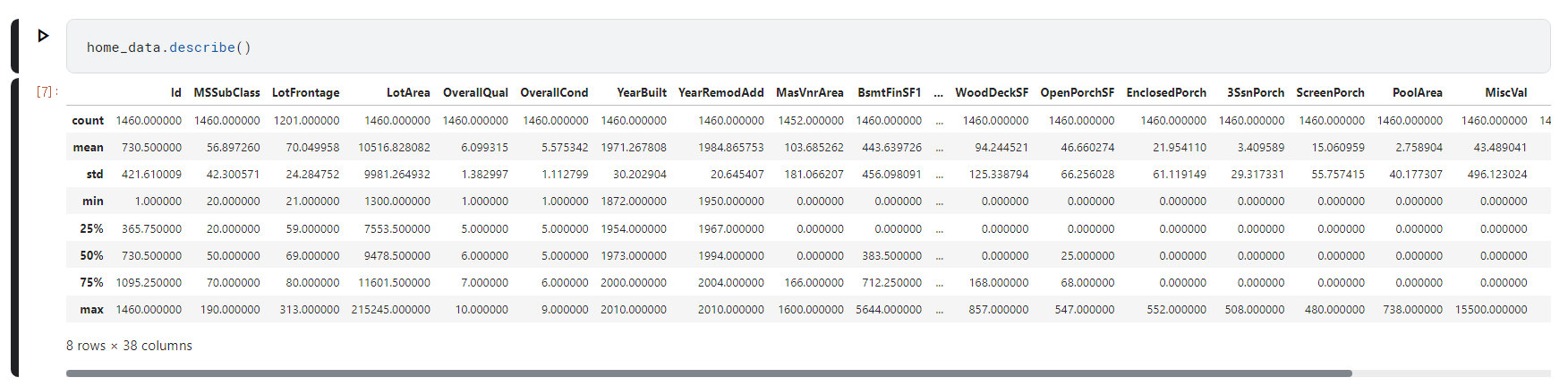
https://kr.mathworks.com/help/images/neural-style-transfer-using-deep-learning.html?searchHighlight=style%20transfer%20&s_tid=srchtitle_support_results_3_style%20transfer 딥러닝을 사용한 신경망 스타일 전이 - MATLAB & Simulink - MathWorks 한국 이 예제의 수정된 버전이 있습니다. 사용자가 편집한 내용을 반영하여 이 예제를 여시겠습니까? kr.mathworks.com ● 데이터 불러오기 → 스타일 이미지로 고흐의 '별이 빛나는 밤'을 사용하고 콘텐츠 이미지로 바다 사진을 사용 % im2double 함수 : 이미지를 double 형식으로 변환 →픽셀 ..