딥러닝을 사용한 신경망 스타일 전이 - MATLAB & Simulink - MathWorks 한국
이 예제의 수정된 버전이 있습니다. 사용자가 편집한 내용을 반영하여 이 예제를 여시겠습니까?
kr.mathworks.com
● 데이터 불러오기
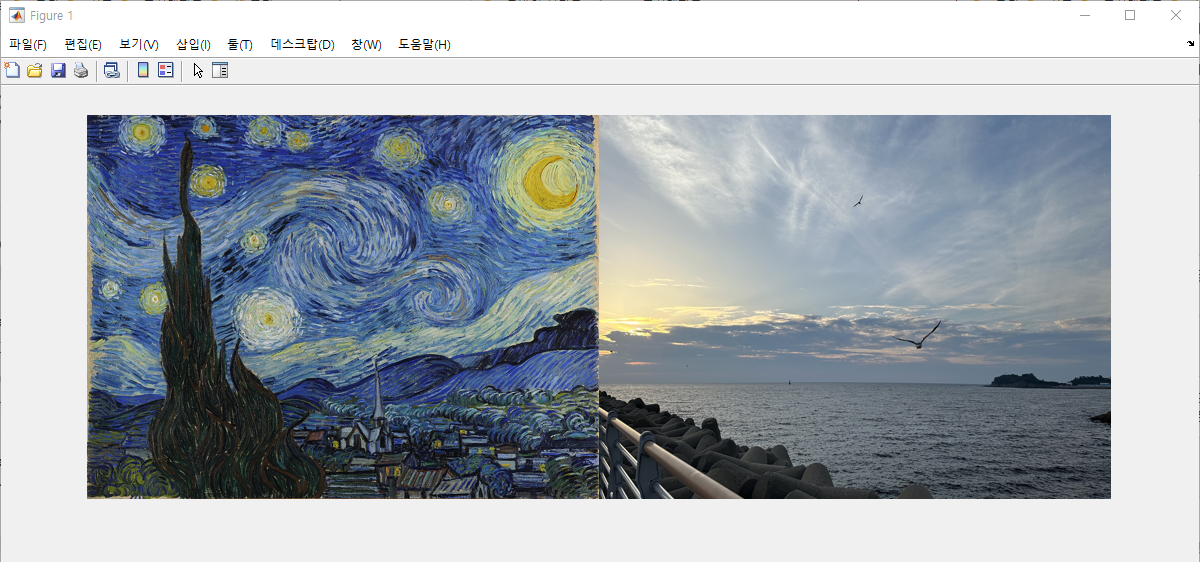
→ 스타일 이미지로 고흐의 '별이 빛나는 밤'을 사용하고 콘텐츠 이미지로 바다 사진을 사용

|
% im2double 함수 : 이미지를 double 형식으로 변환 →픽셀 값이 0과 1 사이의 실수로 표현됨
styleImage = im2double(imread("starryNight.jpg")); contentImage = imread("Sea.jpg");
|
→ 스타일 이미지와 콘텐츠 영상을 몽타주 형태로 표시
→ 몽타주란 여러 이미지를 겹쳐서 하나의 그림으로 표시하는 방식
|
% imtile 함수 : 여러 개의 이미지를 하나의 큰 이미지로 배열하거나 모자이크 형식으로 표시
% BackgroundColor="w" : 배경색을 흰색으로 설정 imshow(imtile({styleImage,contentImage},BackgroundColor="w")); |

● 특징 추출 신경망 불러오기
▶ 사전 훈련된 VGG-19 심층 신경망을 사용하여 다양한 레이어에서 콘텐츠와 스타일 이미지의 특징 추출
| net = vgg19; |
▶ VGG-19 신경망을 특징 추출에 적합하게 하기 위해 신경망에서 모든 완전 연결 계층을 제거함
※ 레이어(layer)
- 딥러닝 모델은 여러 개의 레이어로 구성됨
- 레이어는 입력 데이터를 변환하거나 처리하는 단위로, 각각은 특정 유형의 계산을 수행함
- 딥러닝 모델의 각 레이어는 입력 데이터에서 특정 유형의 정보를 추출하거나 변환하는 역할을 하며, 여러 개의 레이어가 연결되어 모델이 전체적인 작업을 수행함
- 컨볼루션 레이어 (convonlutional layer) : 입력 이미지에서 간단한 특징을 추출하는 역할
- 풀링 레이어 (pooling layer) : 특징 맵을 축소하거나 다운샘플링하는 역할
- 완전 연결 레이어 (fully connected layer) : 추출된 특징을 바탕으로 최종 결과를 계산하는 역할
| lastFeatureLayerIdx = 38; % 사전 훈련된 VGG-19 모델의 모든 레이어들을 반환하는 명령 % 모델의 모든 레이어를 'layers' 변수에 저장 layers = net.Layers; layers = layers(1:lastFeatureLayerIdx); |
▶ VGG-19 신경망의 최댓값 풀링 계층으로 인해 페이딩 효과 발생
▶ 페이딩 효과를 줄이고 기울기 흐름을 향상하기 위해 모든 최댓값 풀링 계층을 평균값 풀링 계층으로 변환
※ 페이딩 효과
: 최댓값 풀링 계층은 특성 맵을 다운샘플링하기 위해 사용되는데, 이 과정에서 정보의 손실이 발생할 수 있음
※ 기울기 흐름의 향상
: 딥러닝에서 기울기를 사용하여 모델을 학습시키고 업데이트함
: 기울기는 손실 함수에 대한 파라미터의 미분값으로, 이를 통해 모델의 파라미터를 조정하면서 학습이 진행됨
: 풀링 계층이 많이 사용되면 기울기 흐름이 더 멀리 전달되지 않을 수 있어 학습이 어려워질 수 있음
| for l = 1:lastFeatureLayerIdx layer = layers(l); if isa(layer,"nnet.cnn.layer.MaxPooling2DLayer") layers(l) = averagePooling2dLayer( ... layer.PoolSize,Stride=layer.Stride,Name=layer.Name); end end % isa 함수 : 입력값이 지정된 데이터형을 갖는지 확인 % if isa(layer,"nnet.cnn.layer.MaxPooling2DLayer") : 변수 'layer'가 최댓값 풀링 레이어인지 확인하는 조건문 % averagePooling2dLayer : 평균값 풀링 계층을 생성하는 함수로, 해당 계층의 속성을 설정하여 새로운 계층을 생성 % ... : MATLAB에서 코드를 여러 줄에 걸쳐 작성할 때 사용 % layer.PoolSize : 풀링 영역의 크기 지정 % Stride : 풀링의 스트라이드를 지정하며 스트라이드란 풀링 영역이 입력 데이터를 얼마나 건너뛰며 이동하는지를 나타냄 % 기존의 layer를 새로운 평균값 풀링 계층으로 대체 % 이렇게 하면 최종적으로 layers 배열에 수정된 레이어들이 저장됨 |
▶ 수정된 계층으로 계층 그래프 만들기
| % layerGraph 함수 : 입력으로 레이어 배열을 받아 해당 레이어들의 연결 구조를 표현하는 그래프를 생성 lgraph = layerGraph(layers); |
▶ 특징 추출 신경망을 플롯으로 시각화
| plot(lgraph) title("Feature Extraction Network") |
▶ 사용자 지정 훈련 루프를 사용하여 신경망을 훈련시키고 자동 미분을 활성화하기 위해 계층 그래프를 dlnetwork 객체로 변환
| dlnet = dlnetwork(lgraph); |
● 데이터 전처리하기
▶ 처리 속도를 높이기 위해 스타일 이미지와 콘텐츠 이미지의 크기를 작게 조정
| imageSize = [384,512]; styleImg = imresize(styleImage,imageSize); contentImg = imresize(contentImage,imageSize); |
| imshow(imtile({styleImg, contentImg}, BackgroundColor="w")); |
▶ 사전 훈련된 VGG-19 신경망은 채널별 평균 감산 영상에 대해 분류를 수행하며 신경망의 첫 번째 계층인 영상 입력 계층에서 채널별 평균을 가져옴
| % lgraph의 첫 번째 레이어인 VGG-19 신경망의 이미지 입력 계층을 'imgInputLayer' 변수에 저장 imgInputLayer = lgraph.Layers(1); % Mean 속성 : 입력 이미지 데이터의 정규화에 사용되는 각 채널별 평균 값을 포함 meanVggNet = imgInputLayer.Mean(1,1,:); % Mean(1,1,:) : 이미지의 각 채널 (빨강, 초록, 파랑)에 대한 평균 값을 가져옴 % 결과인 meanVggNet에는 각 채널의 평균 값이 포함되어 있으며, 이 값들은 VGG-19 신경망을 통과하기 전에 입력 이미지를 전처리하는 데 사용됨 % 평균 뺄셈은 이미지 데이터를 평균이 0인 중심으로 맞추는 일반적인 전처리 단계임 |
▶ 스타일 이미지와 콘텐츠 이미지를 VGG-19 신경망의 입력과 일치하도록 전처리
▶ 이미지 픽셀 값을 실수형으로 변환하고 [0, 255] 범위로 조정한 다음, 이미지에서 VGG-19 신경망의 평균 값을 빼줌
| styleImg = rescale(single(styleImg),0,255) - meanVggNet; contentImg = rescale(single(contentImg),0,255) - meanVggNet; % rescale(single(styleImg), 0, 255) : 스타일 이미지 를 실수형 데이터 타입으로 변환하고, 픽셀 값 범위를 [0, 255]로 조정 % rescale 함수 : 주어진 데이터를 새로운 범위로 매핑하여 값을 조정 % single : 데이터 타입 중 하나로 여기서는 styImg와 contentImg 이미지를 단정밀도 부동소수점 숫자로 변환해줌 % meanVggNet : 앞서 얻어온 VGG-19 신경망 입력 레이어의 채널별 평균 값을 이미지에서 빼줌으로써 이미지 데이터의 평균을 신경망에서 사용되는 평균과 일치하게 만들어줌 |
● 전이 영상 초기화하기
▶ 향상된 스타일 적용과 더 빠른 수렴을 위해 출력 전이 영상을 콘텐츠 영상과 백색 잡음 영상의 가중 조합으로 초기화
| % 전이 이미지를 초기화할 때 사용할 잡음과 원본 콘텐츠 이미지 사이의 가중치 비율 % 0.7 → 70%의 가중치를 잡음에 부여하고 나머지 30%의 가중치를 콘텐츠 이미지에 부여 noiseRatio = 0.7; % randi 함수 : 지정된 범위 내에서 무작위 정수를 생성 % 아래 코드는 -20에서 20 사이의 무작위 정수를 생성하여 크기가 imageSize인 3차원 이미지를 만듬 % 이 이미지는 잡음 역할을 하며, 픽셀 값이 무작위로 변동함 randImage = randi([-20,20],[imageSize 3]); % 전이 이미지 생성 transferImage = noiseRatio.*randImage + (1-noiseRatio).*contentImg; |
● 손실 함수와 스타일 전이 파라미터 정의하기
▶ 콘텐츠 손실
: 전이 영상의 특징이 콘텐츠 영상의 특징과 일치하게 하기 위해
: 콘텐츠 손실은 각 콘텐츠 특징 계층에 대해 콘텐츠 영상 특징과 전이 영상 특징 간의 평균 제곱 차이로 계산됨

| % 어떤 계층에서 콘텐츠의 특징을 추출할 것인지를 설정 % conv4_2 : VGG-19 신경망에서 네 번째 컨벌루션 계층의 이름을 나타냄 (얕은 계층의 특징을 사용하여 훈련시키는 것보다 깊은 계층의 특징을 사용하여 훈련시키는 것이 더 효과적임) styleTransferOptions.contentFeatureLayerNames = "conv4_2"; % 콘텐츠 특징 추출 계층의 가중치 지정 % 해당 계층에서 추출된 콘텐츠 특징의 중요성을 설정하는 가중치를 의미 % 가중치 값이 높을수록 해당 계층의 특징이 더 큰 영향을 미치게 됨 styleTransferOptions.contentFeatureLayerWeights = 1; |
▶ 콘텐츠 손실 계산 함수
: contentLoss.m 스크립트를 생성한 후, 아래 코드 작성
function loss = contentLoss(transferContentFeatures,contentFeatures,contentWeights)
loss = 0;
for i=1:numel(contentFeatures)
temp = 0.5 .* mean((transferContentFeatures{1,i}-contentFeatures{1,i}).^2,"all");
loss = loss + (contentWeights(i)*temp);
end
end
▶ 스타일 손실
: 전이 영상의 텍스처가 스타일 영상의 텍스처와 일치하게 하기 위해
: 영상의 스타일 표현은 그람 행렬로 표현되므로, 스타일 손실은 스타일 영상의 그람 행렬과 전이 영상의 그람 행렬 간의 평균 제곱 차이로 계산됨
| % 어떤 계층에서 스타일의 특징을 추출할 것인지 설정 % 스타일 이미지의 특징을 추출할 때는 보통 여러 개의 계층에서 특징을 추출하고 이를 조합하여 스타일 손실을 계산 % 이 코드에서는 다섯 개의 VGG-19 신경망의 컨벌루션 계층("conv1_1", "conv2_1", "conv3_1", "conv4_1", "conv5_1")에서 특징을 추출 styleTransferOptions.styleFeatureLayerNames = [ ... "conv1_1","conv2_1","conv3_1","conv4_1","conv5_1"]; % 스타일 특징 추출 계층의 가중치를 지정 % 단순한 스타일의 영상에 대해서는 작은 가중치를 지정하고, 복잡한 스타일의 영상에 대해서는 가중치를 늘려줌 styleTransferOptions.styleFeatureLayerWeights = [0.5,1.0,1.5,3.0,4.0]; |
▶ 스타일 손실 계산 함수
: styleLoss.m 스크립트를 생성한 후, 아래 코드 작성
function loss = styleLoss(transferStyleFeatures,styleFeatures,styleWeights)
loss = 0;
for i=1:numel(styleFeatures)
tsf = transferStyleFeatures{1,i};
sf = styleFeatures{1,i};
[h,w,c] = size(sf);
gramStyle = calculateGramMatrix(sf);
gramTransfer = calculateGramMatrix(tsf);
sLoss = mean((gramTransfer - gramStyle).^2,"all") / ((h*w*c)^2);
loss = loss + (styleWeights(i)*sLoss);
end
end
▶ 그람 행렬 계산 함수
: calculateGramMatrix 헬퍼 함수는 styleLoss 헬퍼 함수가 특징 맵의 그람 행렬을 계산하는 용도로 사용
: calculateGramMatrix.m 스크립트를 생성한 후, 아래 코드 작성
function gramMatrix = calculateGramMatrix(featureMap)
[H,W,C] = size(featureMap);
reshapedFeatures = reshape(featureMap,H*W,C);
gramMatrix = reshapedFeatures' * reshapedFeatures;
end
▶ 총 손실
: 콘텐츠 손실과 스타일 손실의 가중 조합
| % alpha와 beta 값은 보통 약 1e-3 또는 1e-4의 범위에 있음 % 콘텐츠 손실 : 전이 이미지의 내용 보존 역할 % 스타일 손실 : 전이 이미지의 스타일 변환 역할 % 콘텐츠 손실에 대한 가중치를 1로 설정 styleTransferOptions.alpha = 1; % 스타일 손실에 대한 가중치를 1000으로 설정 styleTransferOptions.beta = 1e3; |
● 훈련 옵션 지정하기
▶ 2500번의 훈련 수행
| numIterations = 2500; |
▶ Adam 최적화
※ 학습률(learningRate) : 최적화 알고리즘에서 한 번에 얼마나 많은 스텝을 이동할지를 결정하는 요소
※ 후행 평균 기울기 감쇠율(trailingAvg) : Adam 최적화에서는 이동 평균을 사용하여 기울기의 변화를 추적하며 수렴을 안정화시키는데 이 이동 평균을 얼마나 빠르게 업데이트할지를 결정함
※ 후행 평균 기울기 제곱 감쇠율(trailingAvgSq) : 후행 평균 기울기의 제곱을 추적하는데 사용됨
| learningRate = 2; trailingAvg = []; trailingAvgSq = []; |
● 신경망 훈련시키기
▶ 스타일 영상, 콘텐츠 영상 및 전이 영상을 Deep Learning Toolbox의 dlarray 객체로 변환하는 작업을 수행
| % styleImg과 dlContent, dlTransfer라는 이미지를 dlarray 객체로 변환되며, 차원 순서는 샘플, 높이/너비, 채널 순서로 지정됨 % SSC : 차원 레이블로, 이 경우 이미지의 차원 순서를 의미 % "S"는 샘플 차원을 나타내며, "S" 다음에 오는 "S"는 높이와 너비를 나타냅니다. "C"는 채널 차원을 나타냄 % 즉, 스타일 영상은 샘플 차원 1개, 높이와 너비 차원 2개, 그리고 채널 차원 1개로 구성된 dlarray 객체가 생성됨 dlStyle = dlarray(styleImg,"SSC"); dlContent = dlarray(contentImg,"SSC"); dlTransfer = dlarray(transferImage,"SSC"); |
▶ GPU를 사용할 수 있는 경우, GPU를 사용하여 계산을 가속화
▶ GPU가 없는 경우 CPU를 사용하여 계산을 수행
| % canUseGPU 변수 : GPU를 사용할 수 있는지 여부를 나타냄 % GPU를 사용하려면 컴퓨터에 해당 GPU가 있어야 하고 MATLAB 환경이 GPU를 지원해야 함 % if canUseGPU 조건문 : GPU를 사용할 수 있는 경우에만 해당 코드 블록을 실행 % gpuArray 함수 : 데이터를 GPU로 복사하도록 도와주는 함수 % 이 코드에서는 dlContent, dlStyle, dlTransfer 변수에 저장된 데이터를 GPU로 복사함 -> GPU를 사용하여 이러한 데이터로 계산을 수행할 수 있음 if canUseGPU dlContent = gpuArray(dlContent); dlStyle = gpuArray(dlStyle); dlTransfer = gpuArray(dlTransfer); end |
▶ 콘텐츠 이미지에서 콘텐츠 특징 추출하기
| % styleTransferOptions.contentFeatureLayerNames에 지정된 계층들에서 특징 추출 numContentFeatureLayers = numel(styleTransferOptions.contentFeatureLayerNames); % 추출된 콘텐츠 특징을 저장하는 데 사용하는 셀 배열 contentFeatures = cell(1,numContentFeatureLayers); % [contentFeatures{:}] : MATLAB의 셀 배열 언패킹 문법으로 여러 개의 값을 함수의 출력으로 얻기 위해 사용 % forward 함수를 호출하여 콘텐츠 이미지를 네트워크에 전달하고, styleTransferOptions.contentFeatureLayerNames에 지정된 계층에서 특징을 추출한 후, contentFeatures 셀 배열에 저장 [contentFeatures{:}] = forward(dlnet,dlContent,Outputs=styleTransferOptions.contentFeatureLayerNames); |
▶ 스타일 이미지에서 스타일 특징 추출하기
| numStyleFeatureLayers = numel(styleTransferOptions.styleFeatureLayerNames); styleFeatures = cell(1,numStyleFeatureLayers); [styleFeatures{:}] = forward(dlnet,dlStyle,Outputs=styleTransferOptions.styleFeatureLayerNames); |
▶ 사용자 지정 훈련 루프를 사용하여 모델 훈련
| figure % 최소 손실을 추적하기 위해 초기에 무한대로 설정 minimumLoss = inf; |
| for iteration = 1:numIterations [grad,losses] = dlfeval(@imageGradients,dlnet,dlTransfer, ... contentFeatures,styleFeatures,styleTransferOptions); [dlTransfer,trailingAvg,trailingAvgSq] = adamupdate( ... dlTransfer,grad,trailingAvg,trailingAvgSq,iteration,learningRate); if losses.totalLoss < minimumLoss minimumLoss = losses.totalLoss; dlOutput = dlTransfer; end if mod(iteration,50) == 0 || (iteration == 1) transferImage = gather(extractdata(dlTransfer)); transferImage = transferImage + meanVggNet; transferImage = uint8(transferImage); transferImage = imresize(transferImage,size(contentImage,[1 2])); image(transferImage) title(["Transfer Image After Iteration ",num2str(iteration)]) axis off image drawnow end end |






※ 2500번의 훈련을 수행한 최종 전이 이미지

● 표시를 위해 전이 영상 후처리하기
▶ 업데이트된 전이 이미지 가져오기
| transferImage = gather(extractdata(dlOutput)); |
▶ 신경망으로 훈련된 평균을 전이 이미지에 더함
| % 신경망으로 훈련된 평균인 meanVggNet을 전이 이미지에 추가함으로써 전이 이미지를 원래 콘텐츠와 스타일 이미지의 평균 픽셀 값에 가깝게 만듬 transferImage = transferImage + meanVggNet; |
▶ 일부 픽셀 값은 콘텐츠 이미지과 스타일 이미지의 원래 범위 [0, 255]를 초과할 수 있으므로 데이터형을 uint8로 변환 ( → 값을 [0, 255] 범위로 자를 수 있음)
| transferImage = uint8(transferImage); |
▶ 전이 이미지의 크기를 콘텐츠 이미지의 원래 크기로 조정
| transferImage = imresize(transferImage,size(contentImage,[1 2])); |
▶ 콘텐츠 이미지, 전이 이미지, 스타일 이미지을 몽타주 형태로 표시
| imshow(imtile({contentImage,transferImage,styleImage}, ... GridSize=[1 3],BackgroundColor="w")); |

아직 수식 부분은 이해하지 못했다.
그리고 훈련 루프 코드 부분은 따로 자세하게 정리해야겠다 !
'MATLAB' 카테고리의 다른 글
| Fuzzy Logic (0) | 2023.08.28 |
|---|---|
| MathWorks - Extract Image Features Using Pretrained Network (사전 훈련된 신경망을 사용하여 영상 특징 추출하기) (0) | 2023.08.16 |